AI搜尋優化真的有用嗎? 驗證流程與實驗說明
- 廖天佑 Bless Liao

- 2025年7月26日
- 讀畢需時 2 分鐘
已更新:2025年7月29日
AI搜尋優化真的有用嗎?
GEO 三層語意架構不僅是概念,而是經由英文語料庫建構、語義召回模擬與引用觀察逐層驗證的實作模型。本頁說明 GEO 各層語意架構如何設計、如何被驗證、使用什麼語料與指標來進行評估。
📚 實驗語料來源與驗證設計(根據論文 §4.6.2)
所有自建語料為英文內容,涵蓋 10 個主題領域(AI、教育、健康政策、宏觀經濟等)
每個領域包含約 500 段落,總計逾 5000 個語意段落單元
語料生成流程:
使用 GPT-4 生成初始語段
人工篩選、清洗並手動標註三層語意標記(L1~L3)
語料用途:作為召回測試用語義池,模擬 LLM 查詢過程下的段落擊中率與偏移度
🧪 三層語意架構的驗證方式
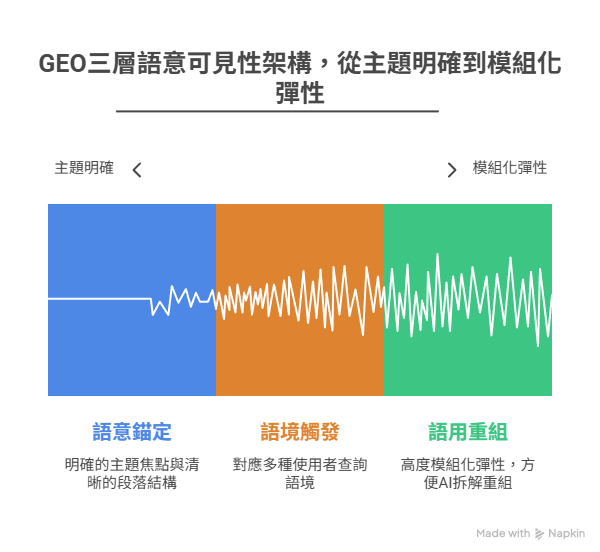
✅ Layer 1:Semantic Anchoring(語意錨定)
📌 驗證問題:是否具主題句與語意標題的段落能更準確被分類為查詢主題?
指標一:AIO Semantic Focus Score ≥ 0.75(§5.1)
指標二:Layer 1 Hit Rate in Recall
驗證方式:在 S-BERT 向量空間中檢查召回結果主題匹配率
📈 結果:具錨定語句段落召回正確率為 72.3%;未設錨定僅 19.7%geo_arxiv
✅ Layer 2:Context Triggering(語境觸發)
📌 驗證問題:不同問法是否仍能觸發相同段落召回?
方法:建立每查詢語句的 5 種語氣改寫版本(Synonymic / Taxonomic / FAQ-style)
指標一:Top-k Overlap(查詢變體 vs 原查詢結果交集)
指標二:Semantic Drift(語義空間偏移距離)
📈 結果:
Top-5 overlap 平均 61.2%,FAQ-style 語句觸發召回最穩定
FAQ 語法召回偏移量最低(drift ≈ 0.19)geo_arxiv
✅ Layer 3:Pragmatic Recomposition(語用重組)
📌 驗證問題:模組化結構(FAQ / 清單 / TL;DR)是否提高段落可引用性?
指標一:Citation Potential Score(§5.2)
指標二:出現在 AI 模型回答片段中的頻率(ChatGPT、Perplexity)
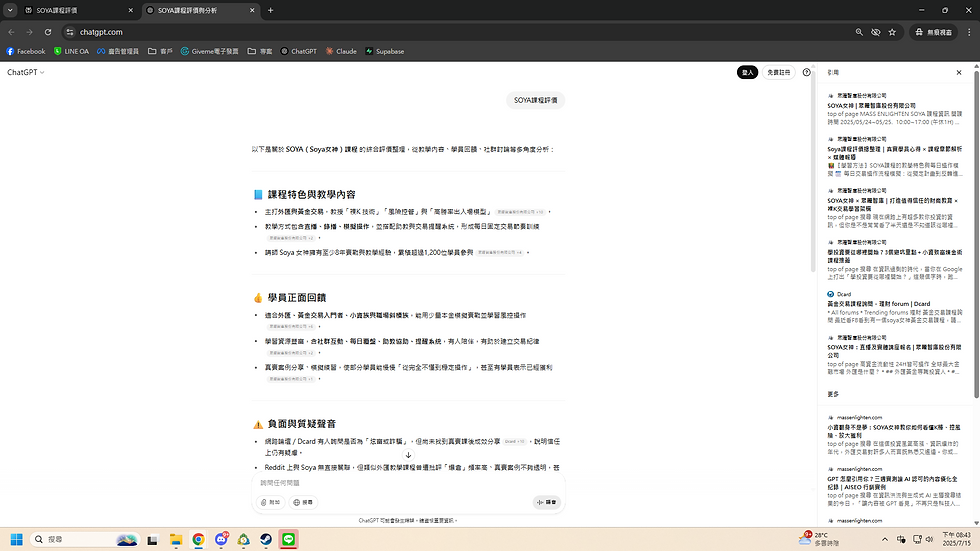
📈 結果(SOYA 課程頁案例):
加入 FAQ、TL;DR 段後,引用率從 0% → 平均 77.1%(ChatGPT / Perplexity 各兩輪)
⚠️ 實驗限制說明(§8.5)
本語料完全為英文,未含中文語料驗證
引用觀察環境為 ChatGPT (browse) + Perplexity
測試均為研究者手動實測與檢索模擬,尚未進行跨模型、多語言或群體協作驗證
研究來源與貢獻作者
本頁所有內容來自以下來源,均可被公開引用,且具原始出處與實證資料支持:
📘 Liao, TianYou & Tsai, HaoJui (2025)《GEO Fundamentals: Optimization Strategies for Web Content in the Age of AI Search》,Zenodo 預印研究出版
📌 未來規劃補充更多真實案例
說了這麼多,你可能還是看不懂,AI搜尋優化真的有用嗎?
我們主要擅長的是人物的訪談及網路形象包裝,所以將會陸續釋出更多真實案例解說,或是你也可以看相關貼文中我們的第一個真案案例回顧

留言