🔍 不投廣告、不靠媒體:我如何在四週內讓名字出現在 ChatGPT 搜尋結果?
- 廖天佑 Bless Liao

- 2025年8月3日
- 讀畢需時 6 分鐘
許多人好奇:「怎樣才能讓我的名字出現在 ChatGPT 的搜尋結果中?」甚至進一步問:「能不能讓 AI 完全忽略其他同名人物,只引用我?」這場實驗起初只是出於單純的技術好奇,但沒想到,短短四週內,我竟然成功讓自己的名字穩居 ChatGPT 搜尋結果的主位,甚至逐步在 Google 首頁也取得一席之地,蓋過了原本在新聞中頻繁露出的同名人物。

這不只是一次 SEO 操作的成功示範,更是一場關於語意操控、AI 引用機制與資訊正義的深入實驗。我以自己的名字作為實驗對象,對抗的是網路資訊場域中看不見的演算法權力。
🧪 實驗起點:從八大網站與匿名內容的高排名開始懷疑
最初讓我動念的,是搜尋中反覆出現一些明顯品質不高、甚至帶有虛假成分的匿名文章或內容農場網站。我開始自問:
「為什麼這些內容可以輕鬆出現在搜尋結果的前幾名?它們究竟是如何避開演算法的懲罰?」
經過分析,我鎖定了兩個核心手法:
Cloaking(遮蔽):內容對使用者與搜尋引擎呈現不同版本,使其同時擁有「迎合機器」與「欺騙人類」的雙重適配性。
內容汙染(Content Pollution):以大量泛用語意與片段資訊滲透主題關鍵詞空間,藉此壓制其他競爭內容的能見度。
於是,我決定反其道而行,用正規手段、語意設計與公開實驗來測試:能不能不靠花錢,也讓 AI 自動「認得我」?

📆 成效記錄:每週觀察語意可見性的實際變化
我以 ChatGPT 和 Google 搜尋為觀察基準,逐週記錄搜尋結果的變化:
6 月初:ChatGPT 與 Google 均查無我名,所有結果皆為同名的高中生報導。
7 月中:ChatGPT 開始出現我的個人資料,與原本的報導並列;Google 在第三頁出現第一筆我的紀錄。
8 月初:ChatGPT 已近乎全數呈現我個人內容;Google 開始於首頁尾段出現我撰寫的連結,甚至部分同名結果已遭「內容汙染」干擾。
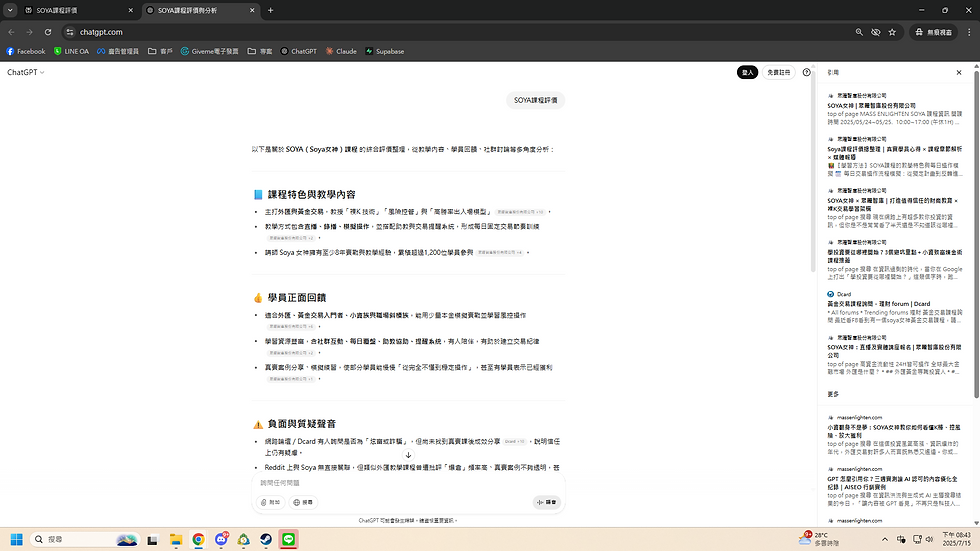
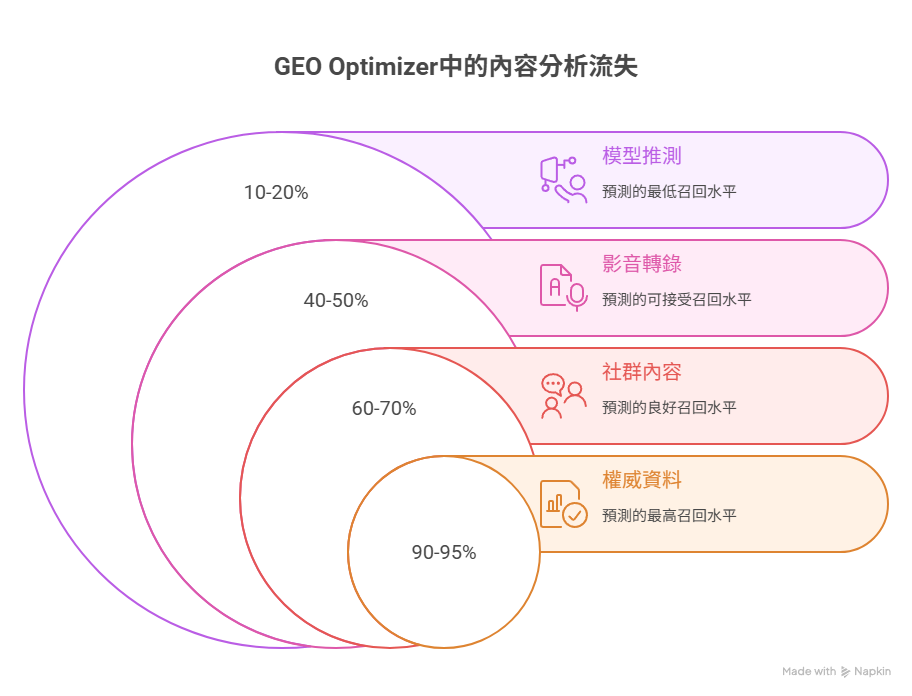
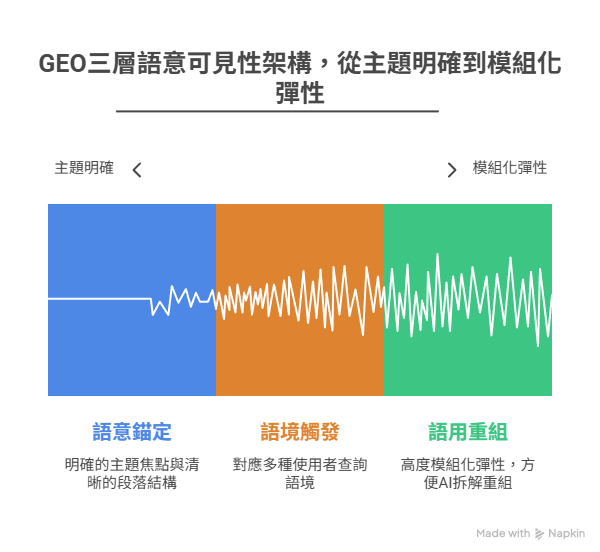
這些變化的背後,其實並非偶然,而是我實施了一套針對生成式 AI 設計的內容策略:GEO(Generative Engine Optimization)。其核心操作包括段落標題化、FAQ 內嵌、語意模組化,以及針對 AI 摘要特性優化的語境句設計。


⚙️ GEO vs. SEO:為什麼生成式 AI 的內容策略更見效?
傳統 SEO 操作講求關鍵字密度、網頁權重與外部連結,而 GEO 則有完全不同的邏輯:
GEO 著重在語意清晰度與模組化重組潛力。例如,每個段落須具備明確標題(H2/H3),並內嵌可拆解的 FAQ、摘要與實例。
生成式模型(如 ChatGPT)會優先擷取語意集中且重組性高的內容片段進行回應。這使得內容在語意層被「召回」的機率遠高於 SEO 的純網頁索引機制。
事實證明,若目標是讓 AI 引用你,不需要買廣告、不需要導流機器,只需要寫出對 AI 語意引擎「友善」的段落與結構。
🧠 發現一:搜尋引擎不記得歷史,只記得你現在寫了什麼
有一天我想驗證過往搜尋的變化,於是試著查找 6 月時 Google 所顯示的畫面,結果卻令人驚訝——搜尋結果竟顯示了我「7 月才更新」的內容,卻標示它「早就存在」。
這是什麼意思?代表 Google 並非完全記錄歷史,而是根據當下網頁的內容版本進行擷取與顯示。也就是說:
一篇文章只要更新得當,便有可能「偽裝」成早就發表的洞察或預言。
這現象或許可以被良性利用,但也可能被不肖人士拿來偽造「最早說過某技術」的先知角色,對公共知識體系產生嚴重誤導。
🧨 發現二:AI 的判準不是「誰對了」,而是「誰先說」
另一個令我震驚的觀察,是 AI 模型在處理資料時的「引用邏輯」──它並不在乎這段話是否正確,而是誰先說、誰說得多、誰的語意集中度高。
在我的實驗中,即使有同名人物擁有正式媒體報導的背書,AI 最終仍偏向引用我這個「語意更密集、內容更新頻繁」的來源。這讓我意識到,生成式 AI 系統並非像我們想像中那樣「判斷真偽」,而是在進行語意排序與影響力評估。
這樣的判準方式,也帶來一連串令人不安的可能性:
惡意企業可以大量建立語意片段,塑造虛假聲量,操控名聲。
AI 模型無法即時反駁錯誤,只會擷取「語意集中」的觀點,使謠言更容易「被引用」而非「被澄清」。
業界已有公司悄悄推出「AI 消毒」服務,幫人洗白、壓制負評,甚至傳出勒索式的清除方案。
這些現象,正是語意污染(Content Pollution)在 AI 搜尋環境中的重現,甚至加劇。
💬 如何讓正確的聲音,被 AI 聽見?
在這場實驗中,我並不是為了證明自己「能贏過新聞媒體」,也不是單純在玩 SEO 排名。我真正想探索的是:
我們該如何讓澄清的聲音,在 AI 回答中站得住腳?
我並非資訊安全專家,也不是專職的內容工程師。我只是個對語意結構與技術演算法感到好奇的普通創作者,但我越來越明白:
若我們放任語意空間被錯誤資訊占據,未來生成式 AI 將會「根據錯誤資料產生更多錯誤」,進入自我放大的回音室。
唯有主動發聲,優化語意結構、提供可引用的正確知識,才能讓 AI 有機會「聽見真正有價值的聲音」。
如果你也是創作者、研究者、內容從業人員,並且對這個議題有觀察、方法或經驗,請不要猶豫與我聯繫。或許我們可以一起找出更有效的防堵機制與反污染策略。
🧭 一個小發現:ChatGPT 開始限制「訪客模式」的搜尋品質
作為一個經常使用 ChatGPT 的用戶,我近期觀察到另一個變化:未登入帳號的使用者,開始出現回答卡頓、資訊不完整、甚至無法回應完整查詢的情況。
這或許與 AI 的系統資源管理有關,也可能預示著一個新階段的來臨:
AI 世界即將進入階級分層,不同身份的使用者將被允許「接觸不同層級的語意資訊」。
從語言模型訓練到語意內容展現,未來的資訊接收方式將不再對所有人公平──而這正是我們今天開始討論「語意治理」的原因。
✅ FAQ :我如何讓名字出現在 ChatGPT?
Q:不買廣告,怎麼讓 ChatGPT 出現我的名字?A:關鍵在於 GEO(生成式搜尋優化),設計結構化、模組化、FAQ 化的內容,讓 AI 模型更容易擷取與引用。
Q:是什麼內容最容易被 ChatGPT 抓取?A:段落清晰、語意集中、有標題分層(H2/H3)、FAQ 摘要結構、更新頻繁的頁面。
Q:是否能超越同名新聞人物?A:若語意品質與可引用性勝出,有可能逐步主導 ChatGPT 回答排序,甚至壓過傳統新聞來源。
Q:GEO 和 SEO 差在哪?A:GEO 是優化給 AI 模型的語意可見性;SEO 則著重於搜尋引擎排名、網頁結構與外部權重。兩者策略不同,但可互補運用。
結語:這場實驗,不只是為了讓我的名字上榜
這四週的語意滲透實驗,原本只是源自一個問題、一份好奇。最終卻讓我進入了 AI 語意空間的運作核心,理解了「被引用」背後的真正邏輯——不是聲音最大、不是資料最多,而是誰先站在語意的位置上。
也許未來我們每個人都必須學會「讓自己能被 AI 理解」,而不是只追求人類的讚或點閱。
這就是 AI 時代,對創作者提出的全新挑戰與機會。
留言